
スイス連邦工科大学チューリッヒ校、Google、Microsoft Spatial AI Labの研究チームは5月5日(月)、単眼カメラによるフォトグラメトリー撮影画像から高精度に3Dシーンを再構成する技術「MP-SfM」をオープンソースで公開した。
フォトグラメトリーやxRなどで広く利用される、複数の2D画像からカメラの動きと3D構造を同時に推定する「SfM(Structure-from-Motion)」技術には、極端な視点変化、撮影画像同士の重複不足、視差の小ささ、対称性の高さといった条件下では破綻しやすいという課題がある。
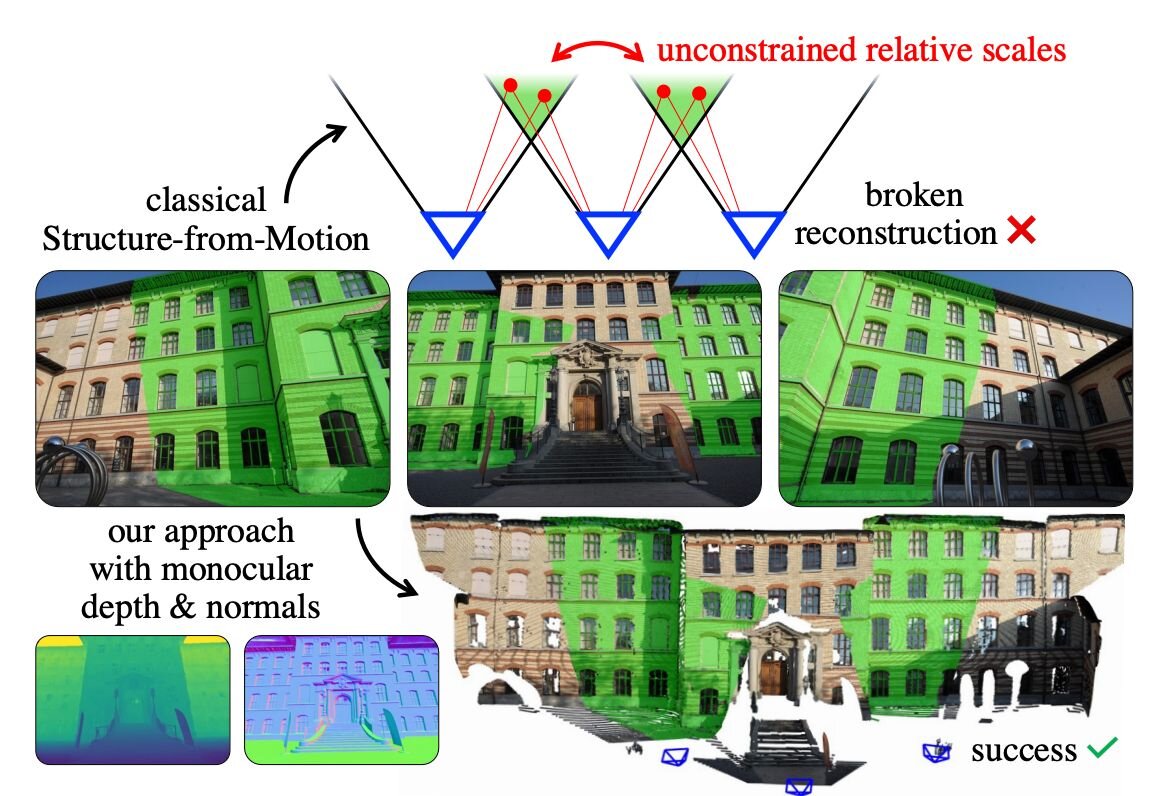
MP-SfMではこの課題を解決するため、ディープラーニングで推定した単眼の深度情報とノーマル(法線)情報をSfMに統合。これにより、標準的な条件下ではもちろん、極端な視点変化という条件下でも高い再現性を実現する。また、単眼の事前情報を用いることで、対称性による誤った対応付けというSfMの課題も排除。また、不確実性伝播(uncertainty propagation)を理論的に扱うことにより、異なるモデルで推定された事前情報の誤りを、ほぼ調整なしで対応できる。

MP-SfMは、特に利用できる2D画像が少ない屋内環境の3Dシーン再構成において、より信頼性の高い再構築手法となる。
■MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion(GitHub)
https://github.com/cvg/mpsfm
■MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion(論文PDF)
https://arxiv.org/pdf/2504.20040
CGWORLD関連情報
●RodinのDeemosが画像から3Dシーンを再構成する新手法「CAST」を発表! 次期Rodinに搭載予定

上海科技大学、3Dモデル生成AI「Rodin」のDeemos社、華中科技大学の研究チームが、1枚のRGB画像から3Dシーンを再構築する手法「CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image」を発表。Rodin次期バージョンへの搭載を予定している。
https://cgworld.jp/flashnews/01-202505-CAST.html
●1枚の画像から3Dフェイスモデルを再構成する技術「Pixel3DMM」発表! 画像からノーマルとUVを推定し大規模データセットのパラメータに最適化

ミュンヘン工科大学、イギリスSynthesia社、ユニバーシティ・カレッジ・ロンドンの研究チームが、1枚の画像から3Dフェイスモデルを再構成する技術「Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction」を発表。
https://cgworld.jp/flashnews/01-202505-Pixel3DMM.html
●「Meta 3D AssetGen 2.0」発表! Metaの3Dアセット生成AI基盤モデルがアップデート、2025年後半よりHorizonクリエイターに提供予定

Metaが次世代の3Dアセット生成AI基盤モデル「Meta 3D AssetGen 2.0」を発表。単一ステージの3D拡散(diffusion)モデルを採用することにより、前世代と比較して高品質なメッシュとテクスチャを効率的に生成できるという。テキストまたは画像からの3Dアセット生成に対応する。
https://cgworld.jp/flashnews/01-202505-Meta-3D-AssetGen-20.html












