最大約50%、平均約20%の処理時間が削減!13の実務工程で徹底比較、32コア/64スレッド搭載 AMD Ryzen Threadripper 7970X × Houdini 実制作レポート

3DCGアニメーションスタジオ・YAMATOWORKSが導入した、BTO PCショップ・サイコムの最新AMD Ryzen™ Threadripper™搭載マシン「Lepton WS4000TRX50A」の実力に迫る本企画。32コア/64スレッドを有し、最新のAMD Ryzen Threadripper 7970Xを搭載した本マシンの実力はいかほどか。
前編ではYAMATOWORKSの制作ワークフローとマシンスペックが求められる背景を中心にレポートした。後編となる今回は、5年前に購入したAMD Ryzen Threadripper 3970Xとの比較を通じて、シミュレーションやレンダリングといった膨大な計算を高速に処理するAMD Ryzen Threadripper 7970Xのマルチスレッド性能から、編集・プレビューといった日々の業務効率をあげるシングルスレッド性能まで、徹底的に検証をしてもらった。
同社CGエフェクトアーティスト・CGアニメーターの北居士龍氏の実務に沿って、Houdiniによる高負荷処理を通じて、32コア/64スレッド搭載本マシンの真価を探る。

Houdiniでの処理スピードを5年前のモデルと最新モデルで比較
前回の記事で紹介したように、北居氏は5年前からすでにサイコムのAMD Ryzen Threadripperマシン「Lepton WS3800TRX40A」をYAMATOWORKS内で使用し、Houdiniでの制作業務に活用してきた。今回、新マシンは旧マシンのAMD Ryzen Threadripper 3970Xから7970Xにアップグレードし、メモリは128GBから256GBへと倍増、GPUもRTX 2060からRTX 5070へと増強。買い換えを前提とした比較環境として申し分ない。
検証環境の詳細
Houdiniのバージョン : Houdini20.5.522
<旧マシンと新マシンの機材構成>

今回は北居氏が自ら考案・制作したHoudiniの検証用シーンを使用して、新旧マシンで13の工程を処理する時間を計測してもらった。「ねらいは、Houdiniのメジャーなシミュレーションとレンダリングをどれくらいの時間で処理できるかを調べること。ハンマーで橋を破壊し、破壊された橋から粉塵が出て、さらに橋の破片が水面に衝突して荒波を発生させ、荒波から白波が発生するという、Houdiniのレガシーのシミュレーションを4つ合体させたシーンを制作しました」(北居氏)。
まずは検証用シーンにおける13の工程について、簡単に解説しておこう。
■工程1:MaterialFractureノードによるモデルの分割
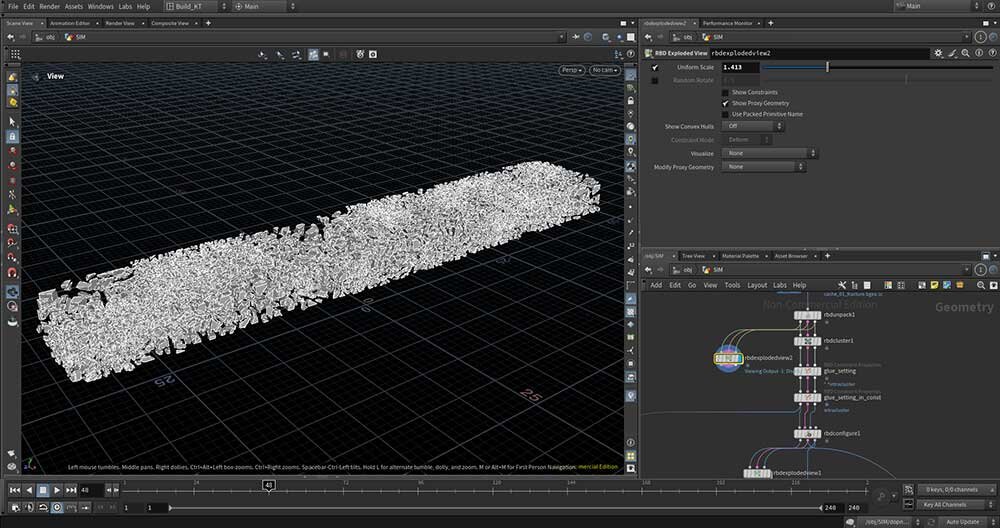
破壊シミュレーションの前準備として3Dモデルを分割する工程。長さ30m×幅5mの橋に見立てたボックスを、MaterialFractureノードのコンクリートプリセットで12,000個の破片に分割した。「MaterialFractureノードにはコンクリートやガラスなど質感のプリセットが用意されていて、各質感に応じた分割感を簡単に作成できます」(北居氏)。
■工程2:RBDシミュレーション
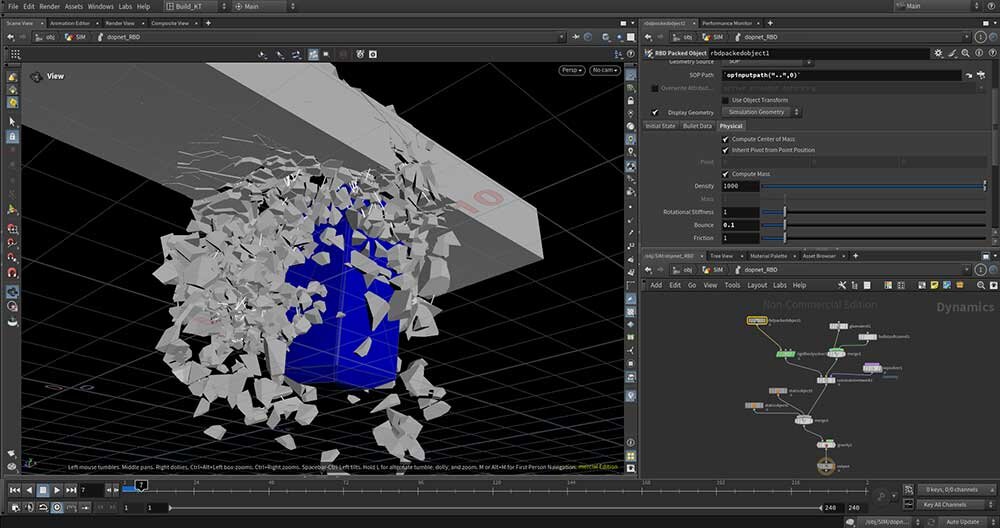
工程1で分割した橋をハンマーで打ち砕く破壊シミュレーション。今回は物理エンジンのBulletで計算し、膨大な破片を効率的に扱えるPackを利用した。「Packを利用すると破片を1個のポイントとして扱えるようになります。膨大なデータの効率処理に重宝しています」(北居氏)。
■工程3:RBDをSDFボリュームにコンバート
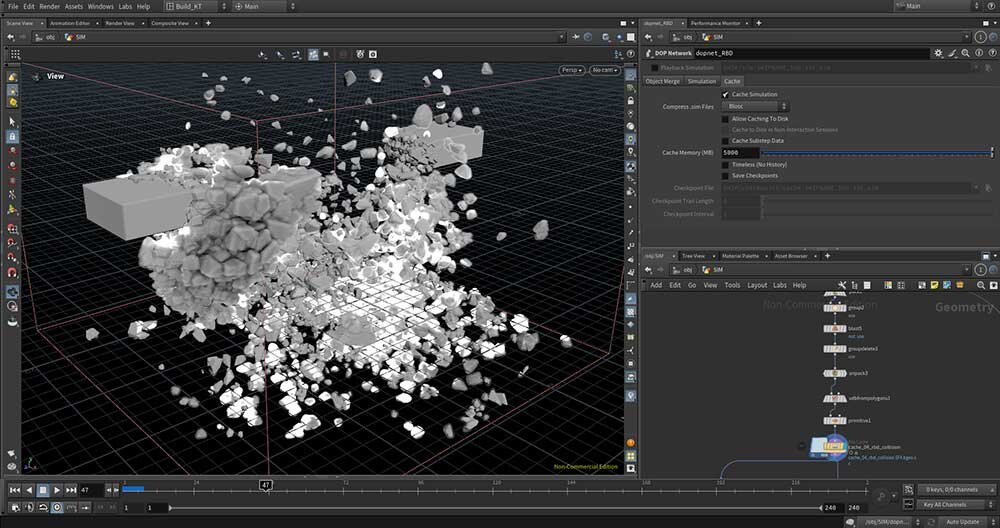
RBDをコリジョンボリュームにコンバートする。次の工程のFLIPで利用する。
■工程4:FLIPシミュレーション
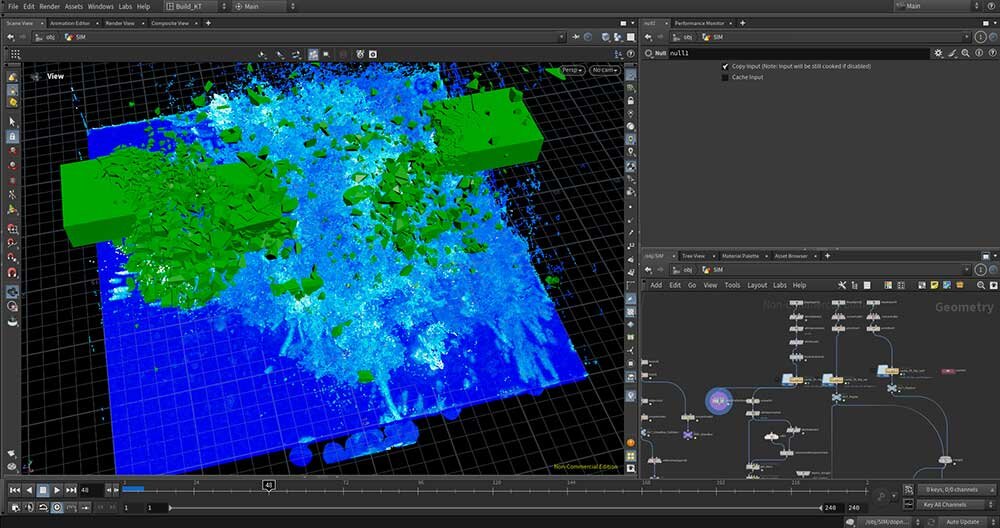
Houdiniでは特に負荷の高いシミュレーションとして知られる、川や海などの流体シミュレーションFLIPの工程。今回は深さ5mの水面に工程3のコリジョンボリュームをぶつけた。なお、セットアップには水の表面付近だけにパーティクルを撒いてシミュレーションを効率化するNarrowBandを選択した。「Particle Separation(粒子間隔、つまりシミュレーション解像度)は0.04です。この距離ならギリギリ実用レベルの解像度だと思います」(北居氏)。
■工程5:FLIPのパーティクルをポリゴン化
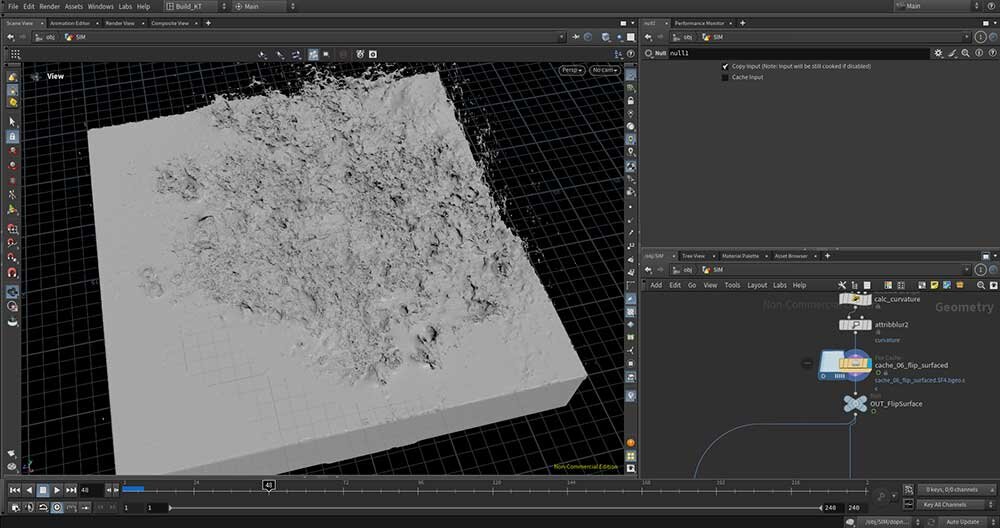
FLIPでシミュレーションした液体はパーティクルとして出力されるため、これを水面としてレンダリングできるよう、パーティクル同士を結合してポリゴン化する。速度からのマスク作成による水面のスムージング、レンダリング時に利用するCurvature(表面曲率)の計算もここで行った。
■工程6:ポリゴンをSDFボリュームにコンバート
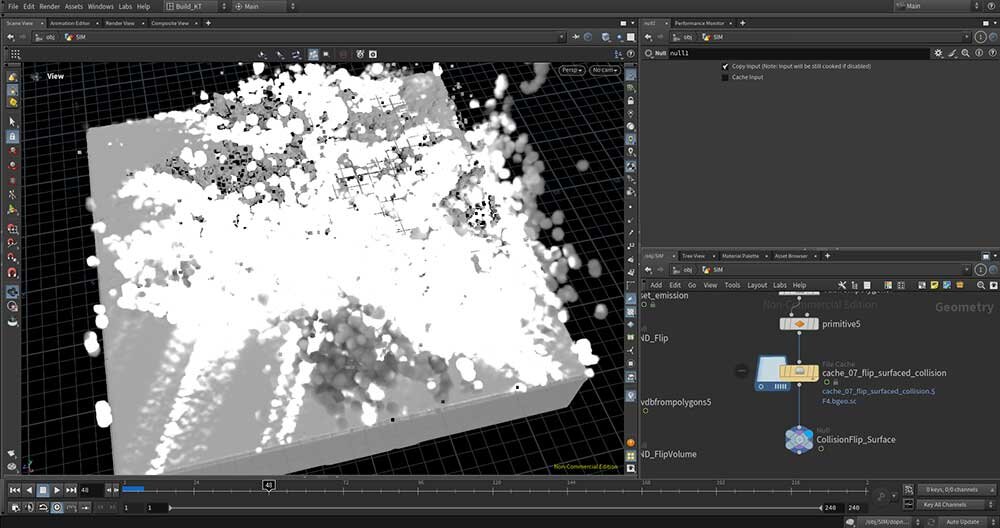
工程3と同様に、FLIPのパーティクルをポリゴン化したデータをコリジョンボリュームにコンバートする。
■工程7:Whitewaterのソースボリューム作成
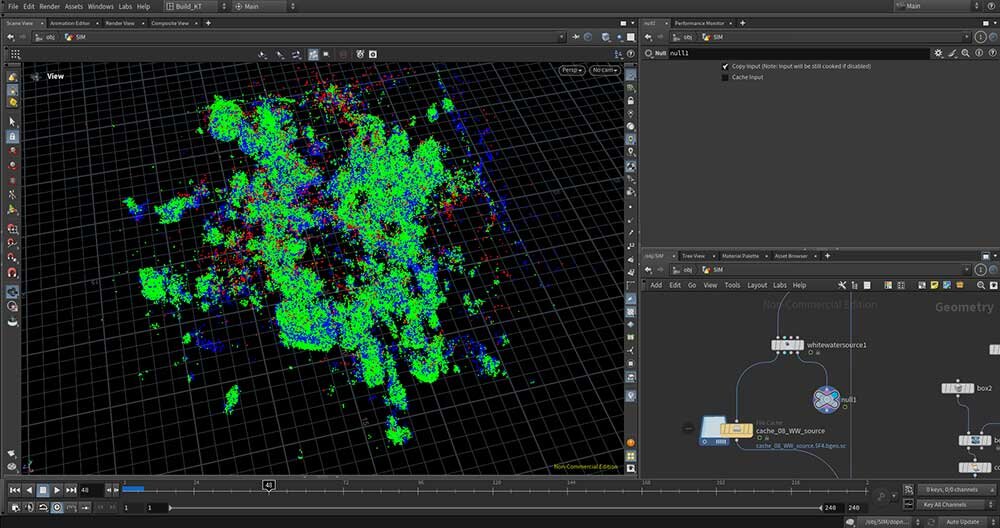
以降は白波(Whitewater)のシミュレーションを行うので、まずはソースになるボリュームを作成する。
■工程8:Whitewaterシミュレーション
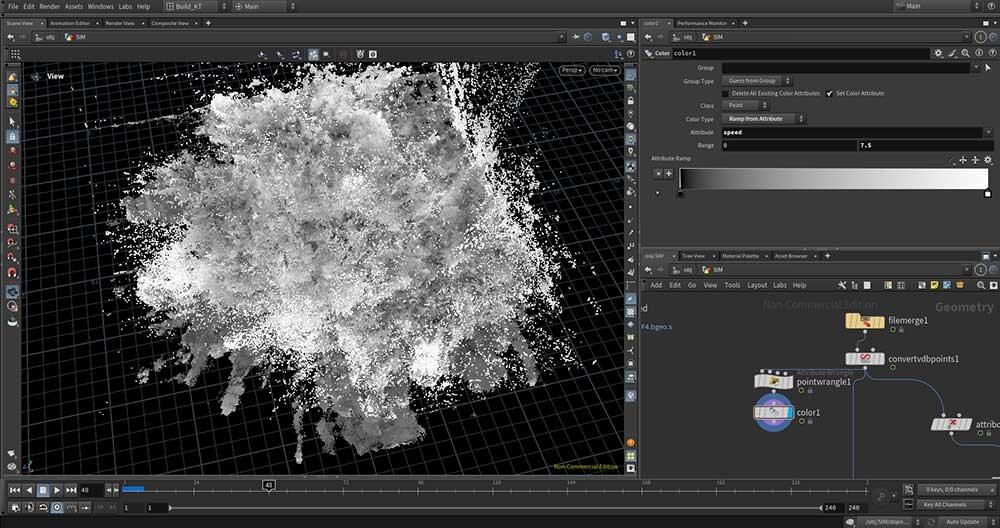
FLIPで作成した水面に対して白波を加える工程。特にメインメモリを消費しやすいシミュレーションのため、あらかじめ計算領域を4分割して個別にシミュレーションを実行する。
■工程9:WhitewaterをVDBボリュームにコンバート
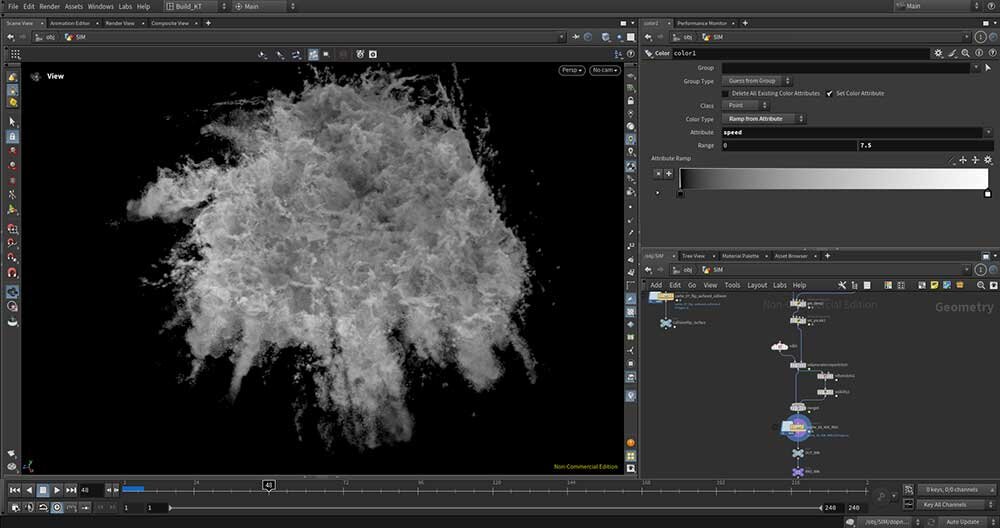
パーティクルとして出力された白波はレンダリング準備のためVDBボリュームにコンバートする。
■工程10:PyroのソースPOP作成
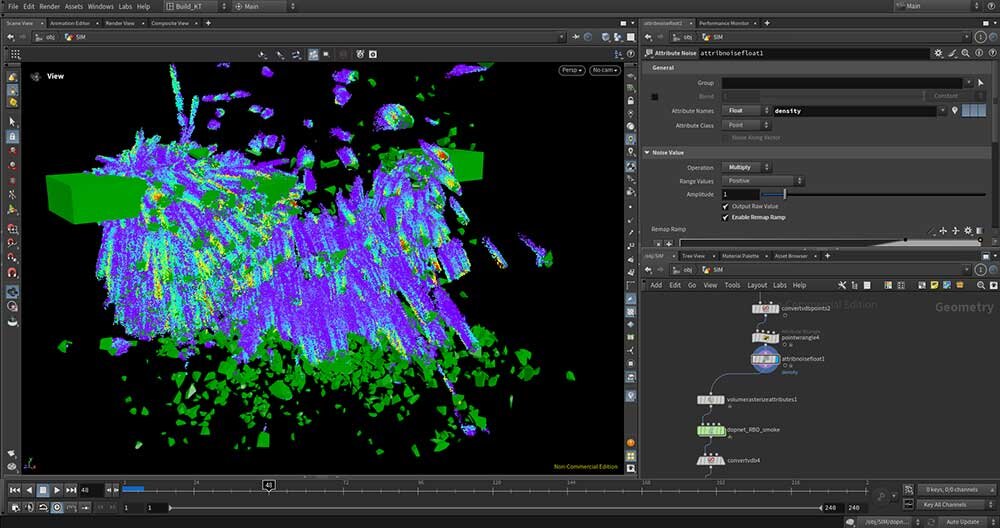
Pyroを使った煙シミュレーションのソースとなるパーティクルを作成する。
■工程11:Pyroシミュレーション
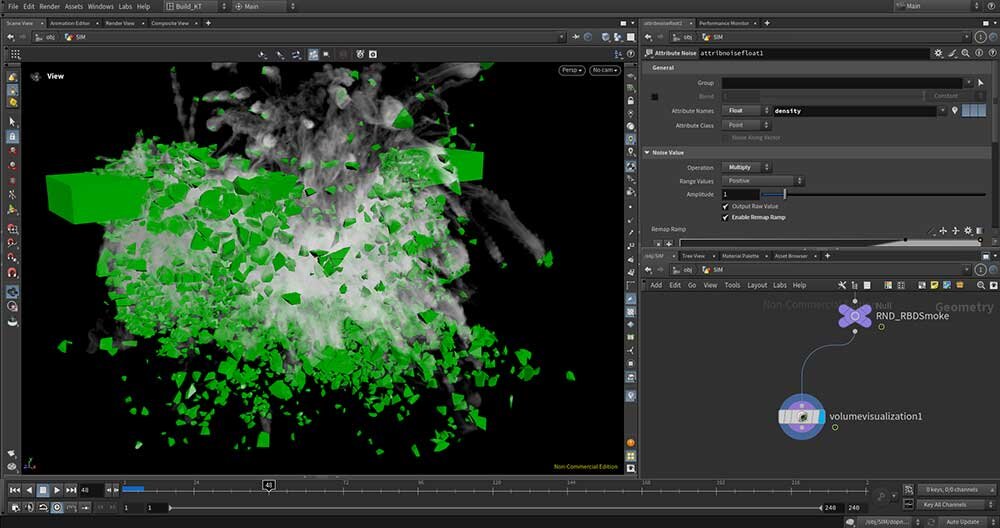
破壊した橋から出てくる粉塵をPyroによる煙シミュレーションで作成する。VoxelSizeは0.04。
■工程12:全データの一括レンダリング
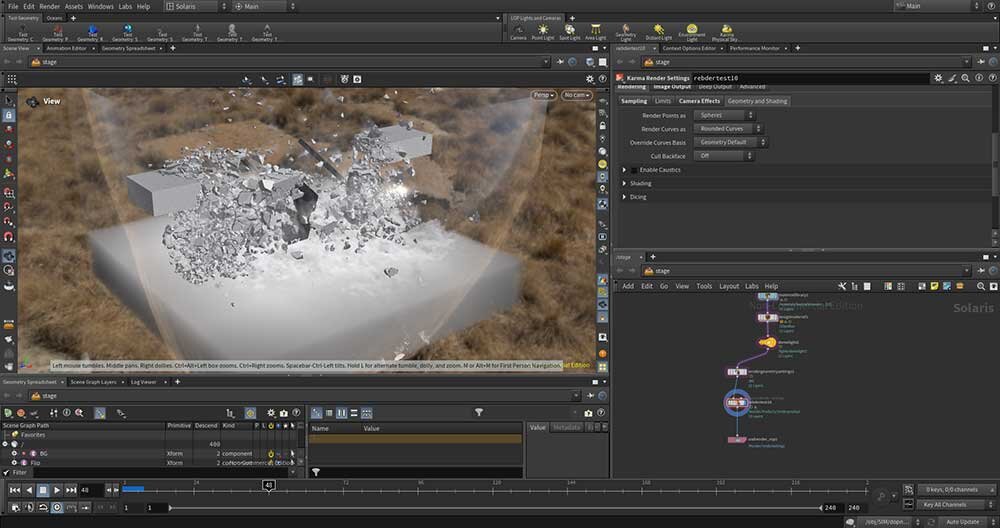
作成した全データを一括でレンダリング。Karma CPU、1,280×720、120フレーム、HDRIのみのライティング、VelocityMotionBlurオン、その他はデフォルトの設定。
■工程13:Wedgeで異なる8つのシミュレーションを同時実行
工程11までとは別に、シミュレーション設定を模索するために利用されるWedge ROPを使い、GlueStrength(破壊されにくさ)のパラメータを変えた8つのシミュレーションを同時に実行する。
<検証結果>最大約50%、平均20%の処理時間短縮を実現
Houdiniの実務に照らした本格的な検証用シミュレーション処理。その結果は、新モデルでは平均20%の時間短縮という良好なものだった。「AMD Ryzen Threadripper 7970Xは、コア数・スレッド数・クロック数の全方位で強化されており、まさに“堅実な進化”を遂げた印象です。今回の検証でも、シミュレーションやレンダリングといったヘビーな処理において、CPUパワーが全体の処理速度を確実に底上げしていることが数値で確認できました。またCPUの性能に加えて、想像よりも強烈に効いているなと感じたのは、メモリの容量や読み書き速度の向上です」と北居氏は満足そうな表情を見せる。
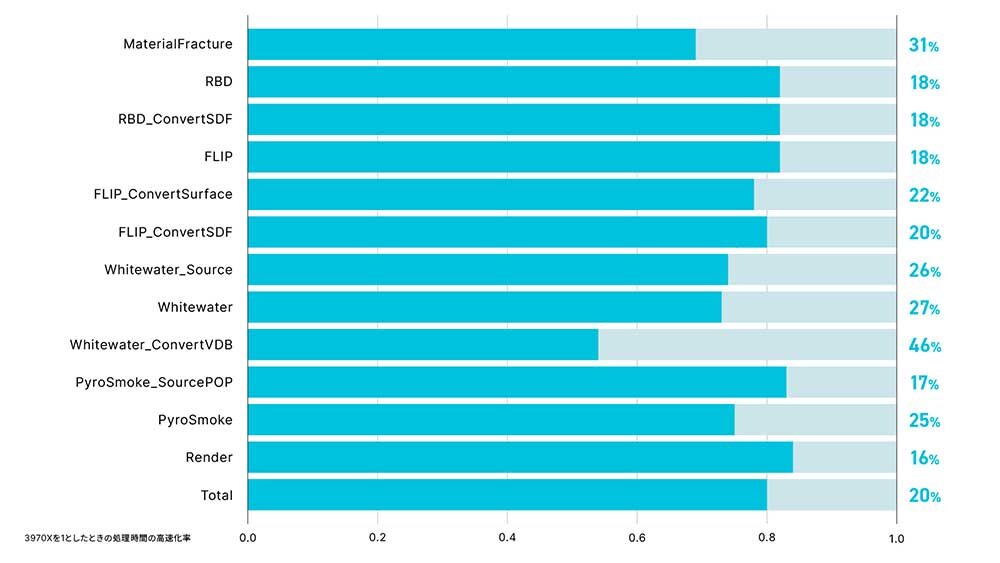
特に差がついたのは「工程9:WhitewaterをVDBボリュームにコンバート」。これは特にメインメモリ容量の差が同時処理フレーム数の差に繋がったことが大きいと北居氏。
「この処理はシミュレーション結果のコンバートなので、シミュレーションのようにフレームを順番に処理する必要がありません。そのため当初は4フレームを並行処理するように設定していました。ただ、旧マシン(メモリ128GB)はメモリ不足により処理が極端に遅くなってしまいました。そこで同時処理は2フレームに減らしました。それでも新マシンは256GBと余裕があり、かなり高速に処理できたようです」。
北居氏はまた、「工程1:MaterialFractureノードによるモデルの分割」でも大きな差がついた点にも注目した。「MaterialFractureノードは、設定によってはシングルスレッドでの処理が必要になるため、以前はAMD Ryzen Threadripperのような多コアCPUにとって苦手な領域でした。ですが、AMD Ryzen Threadripper 7970Xでは動作クロックの向上とアーキテクチャの改良によって、この弱点が大きく改善。旧モデルでは負荷が集中しがちだった処理も、スムーズにこなせるようになり、実際の作業時間にも大きな違いを感じました」(北居氏)。
その他、旧マシンと新マシンで顕著な差が出たのは、「工程7:Whitewaterのソースボリューム作成」「工程8:Whitewaterシミュレーション」「工程11:Pyroシミュレーション」だった。これらはいずれも、大量のパーティクルやボリュームデータを扱う処理であり、メモリ帯域とデータ転送効率がパフォーマンスに直結する領域だ。
「Whitewaterのシミュレーションは、直前のFLIPのデータを参照しながら計算するため、通常よりも多くのデータを扱います。こうした工程ではメモリの読み書き速度が効いてくるのですが、今回はAMD Ryzen Threadripper 7970Xの持つ広帯域メモリサポートや、メモリアクセスを最適化する内部設計がしっかり効果を発揮していました。旧マシンでは処理に時間がかかっていた部分も、非常にスムーズになった印象です」と北居氏は語る。
加えて、PyroではRBDやFLIPの結果とリアルタイムで衝突判定を行いながら、ボリュームベースの煙シミュレーションを走らせるため、大量のデータを複数同時に処理する高負荷な状況が発生する。このようなシーンでも、AMD Ryzen Threadripper 7970Xの多数のコアと大容量キャッシュによる並列処理性能、そして高速なメモリアクセス設計がボトルネックを最小限に抑え、作業時間の短縮に大きく貢献した。
編集時のレスポンスが最大35%高速化──編集もプレビューも“待ち”が激減!
Houdiniでの処理スピードは明らかに向上していたことが明らかとなったが、北居氏はさらにもうひとつの検証を実施してくれた。「オーロラのアセットを開いて、形状などを編集する際の反応速度を調べてみました。これはHoudiniで実作業を行う際の反応スピードや作業快適性、いわば“瞬発力”を調べるのがねらいです」(北居氏)。
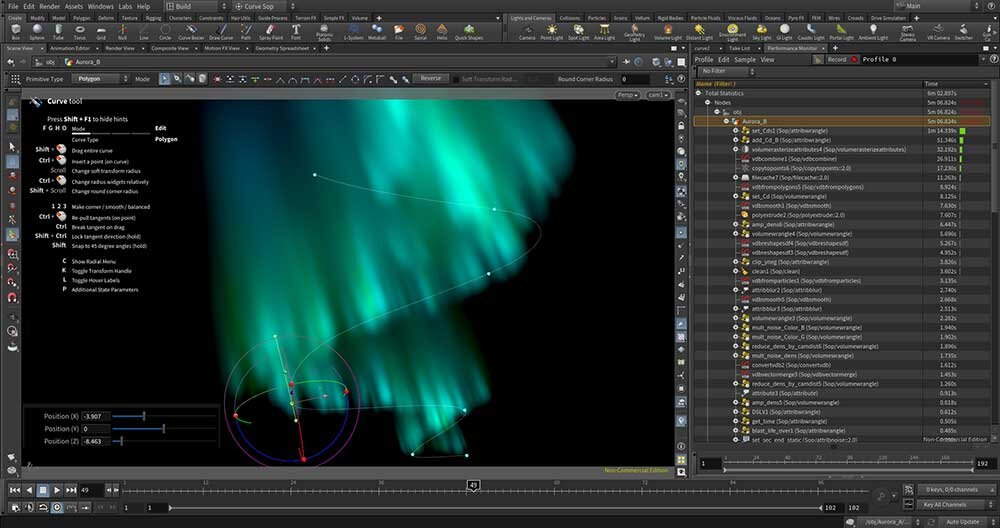
検証の結果、体感・数値共に大きく向上していることが判明した。「新旧マシンで画面録画をしてありますのでそれ(下記)を見てください。AMD Ryzen Threadripper 7970Xは、インタラクティブな操作時の応答性にも優れており、ノードを追加したり設定を変更した際の反応が非常に軽快になった印象です。Houdiniで作業する上での“体感速度”がこれほど向上したのは、シングルスレッド性能の強化によるものと考えられます。これとは別に48フレーム分のFlipBook(プレビュー動画)の作成でも、AMD Ryzen Threadripper 7970Xの真価が発揮されました。1フレームずつ処理していくタイプのこの作業では、CPUの演算能力がダイレクトに処理時間に影響します。実際、旧モデルに比べて約35%もの高速化を実現しており、AMD Ryzen Threadripper 7970Xが高い実効性能を持つことが証明されました」と北居氏は驚きを見せる。
なお、検証に使用したオーロラのアセットは、AMD Ryzen ThreadripperがよりそのCPUパワーを発揮しやすいように北居氏がWrangleノード※を使用して組み立てたものだ。
※Wrangleノード Houdini内のプログラム言語VEXで利用できるノードで、マルチスレッドで処理できるSIMD(Single Instruction Multiple Data)方式の命令を記述できる
マルチもシングルもパワフルに進化──AMD Ryzen Threadripper 7970Xが叶える理想のワークステーション環境
今回の検証を終えて北居氏は、これまで同様AMD Ryzen ThreadripperがCPUとして着実にパワーを向上させていることを実感しただけでなく、「Lepton WS4000TRX50A」がバランスの取れたスペックのマシンになっている点を評価。

「以前は“シングルスレッドが弱点”と言われがちだったAMD Ryzen Threadripperですが、7970Xではその印象を大きく覆す進化を遂げています。多コアによる同時処理性能はそのままに、1コアあたりの性能も着実に向上し、インタラクティブな作業から重たい計算処理まで、あらゆる局面で快適な制作環境を実現してくれました。また、メインメモリの容量や速度向上などを目の当たりにして、今回のサイコムのLepton WS4000TRX50Aがワークステーションとして良いバランスのマシンだなと実感しました。会社でも自宅でも、引き続き使っていきたいです」と北居氏は語った。
TEXT__kagaya(ハリんち)
EDIT_中川裕介(CGWORLD)












