
スタンフォード大学、バイトダンス・シード、ジョンズ・ホプキンズ大学、香港中文大学、バイトダンスからなる研究チームは9月4日(月)、一貫性のある1分超の動画を生成するAI技術「Mixture of Contexts for Long Video Generation」を発表した。動画生成AIが、重要な部分だけを動的に選び出して参照することで長尺動画の学習と生成を効率化し、短尺動画とほぼ同じ計算コストで長尺動画を生成できるという。
How do we generate videos on the scale of minutes, without drifting or forgetting about the historical context?
— Gordon Wetzstein (@GordonWetzstein) September 4, 2025
We introduce Mixture of Contexts. Every minute-long video below is the direct output of our model in a single pass, with no post-processing, stitching, or editing.
1/4 pic.twitter.com/BBs61tuKQp
How do we generate videos on the scale of minutes, without drifting or forgetting about the historical context?
We introduce Mixture of Contexts. Every minute-long video below is the direct output of our model in a single pass, with no post-processing, stitching, or editing.
どうすればAIは、数分にわたる動画を、内容が破綻したり過去の文脈を忘れたりせずに生成できるのでしょうか?
その答えが「Mixture of Contexts」です。ここに掲載する1分間の動画は全て、私たちのモデルがシングルパスで生成したものです。ポスプロや編集、つなぎ合わせは一切ありません。
Mixture of Contexts is a learnable sparse attention routing mechanism that dynamically selects relevant contexts to attend to, enabling efficient training and inference on long videos: minute-scale context memory with short clip computation cost.
— Gordon Wetzstein (@GordonWetzstein) September 4, 2025
2/4 pic.twitter.com/NX84p3OYmW
Mixture of Contexts is a learnable sparse attention routing mechanism that dynamically selects relevant contexts to attend to, enabling efficient training and inference on long videos: minute-scale context memory with short clip computation cost.
Mixture of Contextsは関連性の高い文脈(コンテキスト)を動的に選択する、学習可能なスパース・アテンション・ルーティング機構です。これにより、長尺動画の学習と生成を効率化し、短い動画とほぼ同じ計算コストで、1分尺の記憶と一貫性を実現します。
This is a step forward for long-context video tuning, which has already unlocked impressive multi-shot video generation pipelines from @0xFramer. Generating minutes- or even hour-long videos without drifting or forgetting is not "coming soon" -- it is already here.
— Gordon Wetzstein (@GordonWetzstein) September 4, 2025
3/4 pic.twitter.com/bzEUNBbEV7
This is a step forward for long-context video tuning, which has already unlocked impressive multi-shot video generation pipelines from
@0xFramer. Generating minutes- or even hour-long videos without drifting or forgetting is not "coming soon" -- it is already here.
これは、Framer氏らによる素晴らしいマルチショット動画生成を可能にした、長文脈動画チューニングの分野における大きな一歩です。内容が破綻したり忘れたりすることなく、数分、さらには1時間にも及ぶ動画を生成する技術は、「もうすぐ来る」未来の話ではありません。——それは、すでにここにあります。
従来の動画生成AIは、新しいフレームをつくる際に、それまで生成した全過去フレームを参照しようとする(Dense Self-Attention、密な自己注意機構)。この手法の問題点は、動画が長くなればなるほど、参照すべき過去フレーム量が指数関数的に増加すること。「Mixture of Contexts」では、「必要な情報だけを検索して取り出す(sparse attention routing、スパース・アテンション・ルーティング)」というアプローチでこの問題を解決する。
Mixture of Contextsは、動画の文脈(コンテキスト)を、チャンク化(Chunking、シーケンスを意味あるブロックに分割)、ルーティング(Routing、各チャンクの要約だけを見て関連性の高いチャンクのみを選び出す)、必須アンカーの追加(Mandatory Anchors、品質と一貫性維持のため、テキストプロンプトと直前の数フレームは常時参照するよう固定)、限定的なアテンション計算(fine-grain attention on the pruned set、選出した少数のチャンクと必須アンカーだけに注意を向けて計算)の手順で計算する。
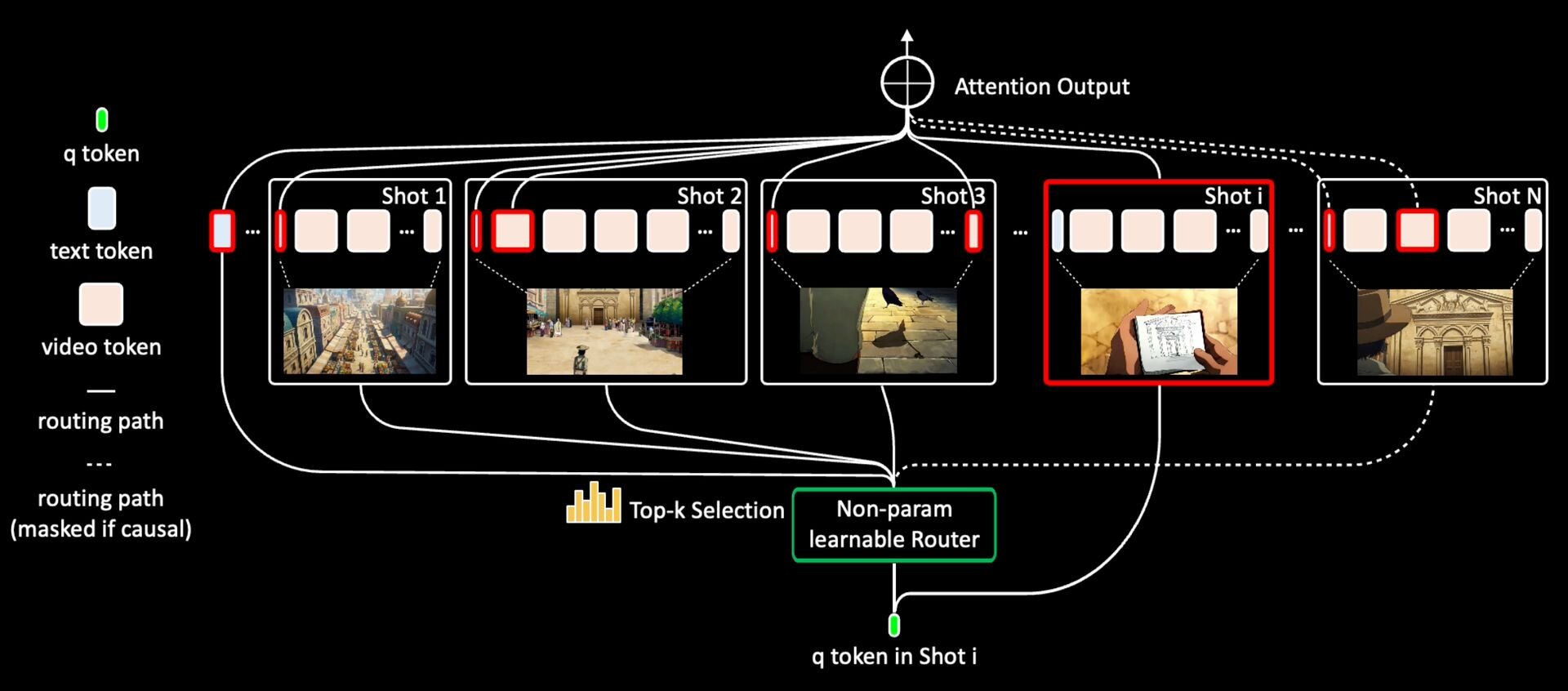
本技術を用いることにより、参照すべきトークンのペアが約85%削減、アテンション計算の計算量(FLOPs)が最大7分の1に削減、1分規模の動画生成がエンドツーエンドで2.2倍に高速化。また、計算量が大幅に削減されながらも、一貫性や動きの滑らかさ、美しさなどは従来と同等、または項目によっては向上したという。
■Mixture of Contexts for Long Video Generation “Minute-long context memory with short-video cost”(プロジェクトページ、英語)
https://primecai.github.io/moc/
■Mixture of Contexts for Long Video Generation(Hugging Face Paper page)
https://huggingface.co/papers/2508.21058
CGWORLD関連情報
●AIプラットフォーム「KREA」がリアルタイム動画生成機能を新搭載! ベータテスター募集中

Krea AIが画像・動画生成AIプラットフォーム「KREA」にリアルタイム動画生成機能を追加。現在はベータテスト段階で、機能の利用には待機リスト(Wait List)への登録が必要となる。
https://cgworld.jp/flashnews/01-202509-KREA-realtime.html
●アリババの動画生成AIモデル「Wan2.2」公開! MoEアーキテクチャ、シネマティックコントロールシステム搭載、3種モデルをオープンソースで提供

アリババグループが世界初のオープンソースMoE(Mixture-of-Experts)動画生成AIモデル「Wan 2.2」をGitHubとHugging Face、同社運営の機械学習モデルプラットフォーム「ModelScope」でそれぞれ公開。テキストまたは画像からの動画生成と、両者のハイブリッドモデルを合わせた3種類のモデルがフルオープンソース(Apache-2.0ライセンス)で提供される。
https://cgworld.jp/flashnews/01-202508-Wan22.html
●画像生成AI「Akuma.ai(現Anirole)」の新機能「リアルタイム生成 v2」リリース! 大ざっぱな描画や画像からリアルタイムでイラストを生成

Kinkakuが画像生成AIサービス「Akuma.ai(現Anirole)」に「リアルタイム生成 v2」機能を追加、公開。2024年3月にリリースしたリアルタイム画像生成機能「AIキャンバス」の後継機能で、同社によるとクオリティは4倍になったという。
https://cgworld.jp/flashnews/01-202507-Akuma-ai.html












