
サイモンフレーザー大学、エレクトロニック・アーツ、カナダ国立研究機構、NVIDIAからなる研究チームは9月16日(火)、モーションキャプチャデータに含まれるアーティファクト(不自然な動き)を自動で修正する新しい手法「StableMotion」を発表し、オープンソース(MITライセンス)で公開した。
「StableMotion」は、センサーを使用してモーションキャプチャを行う都合上避けられない、動きがカクつきや一瞬の停止などのアーティファクトを、機械学習を用いて自動修正できる手法。従来のAIによる修正手法では、「破損したデータ」と「手作業で綺麗に修正したデータ」のペア、つまりクリーンな教師データを大量に用意してモデルを学習させる必要があった。しかしStableMotionでは、ペアではない破損したデータのみを用いて学習させることができ、綺麗なデータを用意する必要がない点が特長となる。
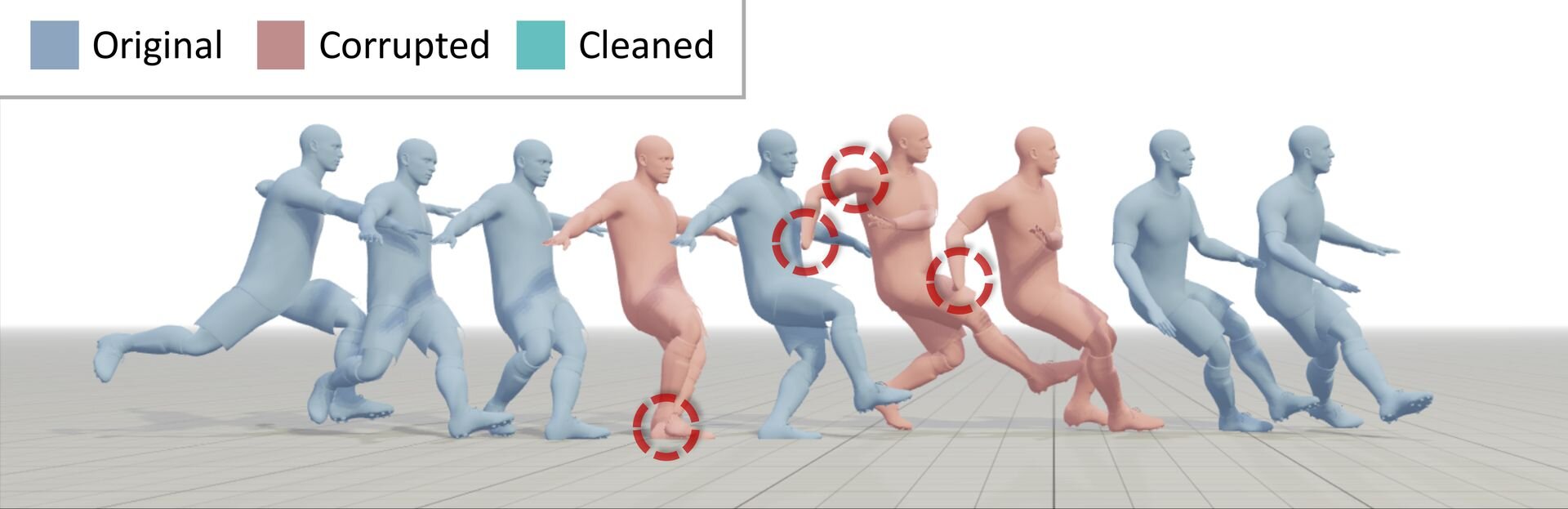

StableMotionではまず、データ内の各フレームが高品質か低品質かを示す「motion quality indicators(品質インジケーター)」というラベルを付与。そしてモデルはこのインジケーターを手がかりに、モーションの品質を識別する能力と、指定された品質のモーションを生成する能力を同時に学習する。実データの修正時には、モデルがまず破損しているフレームを識別し、その部分に対して「高品質なモーションを生成せよ」というプロンプトを与えることで補完・修正する。
[1/6]Data-driven models are often sensitive to noisy training data—the cleaner the data, the better the results. But not StableMotion.
— Yuxuan Mu (@YuxuanMu16173) September 15, 2025
Inspired by state-return trajectory modeling in offline RL, we incorporate a frame-level quality indicator variable (QualVar). Our framework… pic.twitter.com/dVttT9p5oy
Data-driven models are often sensitive to noisy training data—the cleaner the data, the better the results. But not StableMotion.
Inspired by state-return trajectory modeling in offline RL, we incorporate a frame-level quality indicator variable (QualVar). Our framework utilizes a generate-discriminate approach, where a model is jointly trained to evaluate motion quality and generate motion of varying quality, according to QualVar.従来、データを使って学習するAIモデルは「学習データが綺麗であればあるほど、良い結果が出る」というのがこれまでの常識でした。しかしStableMotionは違います。私たちは、AIの学習手法の一種である「オフライン強化学習」の考え方からヒントを得ました。強化学習では、AIの行動が良いか悪いかを「報酬」という数値で教えます。これと同じように、私たちはモーションの1コマ1コマに対して、その品質の良し悪しを示す「quality indicator(品質インジケーター)」変数(QualVar)を導入します。このQualVarを手がかりとして、StableMotionのモデルは、「識別する能力:モーションの品質が良いか悪いかを見分ける」能力と「生成する能力:指示された品質でモーションを新しくつくり出す」能力、2つを同時に学習していきます。
[2/6]Similar to the practice of prompting text-to-image model with “photo-realistic quality”, QualVar offers a knob to specify the generation quality. The model can cleanup raw mocap data by first identifying corrupted segments and then inpainting them with high-quality… pic.twitter.com/bEDQKjuxhU
— Yuxuan Mu (@YuxuanMu16173) September 15, 2025
Similar to the practice of prompting text-to-image model with “photo-realistic quality”, QualVar offers a knob to specify the generation quality. The model can cleanup raw mocap data by first identifying corrupted segments and then inpainting them with high-quality motions.
これは、画像生成AIに「写真のようにリアルな品質で」とプロンプトを与えて画像を生成させるやり方と似ています。それと同じように、品質インジケーター変数(QualVar)は、生成したいモーションの品質を指定するための「調整つまみ」のような役割を果たします。この「調整つまみ」の仕組みを使って、モデルは生のモーションキャプチャデータを「特定」と「補完(インペインティング)」の2段階のプロセスでクリーンアップします。
[3/6]In a production scenario, we apply StableMotion to train a motion cleanup model on SoccerMocap, a 245-hour raw motion capture dataset captured by a prominent game studio. pic.twitter.com/CqYOnxmg3h
— Yuxuan Mu (@YuxuanMu16173) September 15, 2025
In a production scenario, we apply StableMotion to train a motion cleanup model on SoccerMocap, a 245-hour raw motion capture dataset captured by a prominent game studio.
プロダクションシナリオとして、私たちは「SoccerMocap」というデータセットを使い、StableMotionでモーション修正モデルを学習させました。このデータセットは、ある著名なゲームスタジオによって収録された、合計245時間にも及ぶ、一切修正が加えられていない生のモーションキャプチャデータセットです。
[4/6]With StableMotion, motion cleanup models can be effectively trained even on datasets exhibiting severe motion corruptions. pic.twitter.com/dJBJIvfpsG
— Yuxuan Mu (@YuxuanMu16173) September 15, 2025
With StableMotion, motion cleanup models can be effectively trained even on datasets exhibiting severe motion corruptions.
StableMotionを使えば、たとえアーティファクトが非常に深刻なデータセットを使ったとしても、モーションを修正するためのモデルを効果的に学習させることが可能です。
[5/6] Several test-time scaling techniques are designed, which harness the sample diversity and the dual functionality of the generate-discriminate model to improve consistency and preservation of the content in the original motion clips. pic.twitter.com/9VthkpUMxT
— Yuxuan Mu (@YuxuanMu16173) September 15, 2025
Several test-time scaling techniques are designed, which harness the sample diversity and the dual functionality of the generate-discriminate model to improve consistency and preservation of the content in the original motion clips.
さらに、学習させたモデルを実際に使ってモーションを修正する段階(テスト時)で、結果の質をさらに向上させるためのテクニックもいくつか考案しました。これらのテクニックは、StableMotionのモデルが持つ、一度の指示で多様なパターンのモーションを生成できることと、「生成する能力」と「品質を識別する能力」の両方を持つことを上手く活用するものです。これらの特性を活用することで、修正結果の安定性を高めると同時に、元のモーションが持つ本来の動きをできるだけ壊さずに維持することが可能になります。
■StableMotion: Training Motion Cleanup Models with Unpaired Corrupted Data(プロジェクトページ、英語)
https://yxmu.foo/stablemotion-page/
■StableMotion: Training Motion Cleanup Models with Unpaired Corrupted Data(GitHub)
https://github.com/Murrol/StableMotion
CGWORLD関連情報
●NVIDIAの新AIモデル「LuxDiT」発表! 単一画像・動画から高品質なHDR環境マップを生成できる拡散トランスフォーマー

NVIDIA、トロント大学、ベクター人工知能研究所からなる研究チームが、1枚の画像・動画からその場所のリアルなライティングを推定し、高精度なHDR環境マップを生成できるDiT(Diffusion Transformer、拡散トランスフォーマー)、「LuxDiT」を発表。コードは近日公開される予定。
https://cgworld.jp/flashnews/01-202509-LuxDiT.html
●NVIDIAが3DGS技術「LongSplat」発表! スマホで撮影したカジュアルな動画から空間の3DGSモデルを生成し、自由な視点の映像をつくり出す

国立陽明交通大学とNVIDIAの研究チームが、スマートフォンなどで気軽に撮影した長尺かつ複雑な動きを含む動画から3D Gaussian Splattingモデルを生成し、新しい視点の画像を生成するフレームワーク「LongSplat」を発表。GitHubではNVIDIAライセンスでコードが公開されている。
https://cgworld.jp/flashnews/01-202509-LongSplat.html
●NVIDIA、新リライティングフレームワーク「UniRelight」発表! 入力画像または動画からシーン特性と照明分布を分析し高品質なリライトを実現

NVIDIA、トロント大学、Vector Instituteからなる研究チームが新しいリライティング(再照明)フレームワーク「UniRelight」を発表。1枚の入力画像または動画からシーンの固有特性と照明分布を共同でモデル化することで、高品質なリライティングと固有分解を可能にする。
https://cgworld.jp/flashnews/01-202507-NVIDIA-UniRelight.html












