
NVIDIA、トロント大学、ベクター人工知能研究所からなる研究チームは9月6日(水)、1枚の画像・動画からその場所のリアルなライティングを推定し、高精度なHDR環境マップを生成できるDiT(Diffusion Transformer、拡散トランスフォーマー)、「LuxDiT」を発表した。コードは近日公開される予定。
Introducing LuxDiT: a diffusion transformer (DiT) that estimates realistic scene lighting from a single image or video.
— Ruofan Liang (@RfLiang) September 5, 2025
It produces accurate HDR environment maps, addressing a long-standing challenge in computer vision.
Paper: https://t.co/6cW6WlREBl pic.twitter.com/gZE1HCk3hy
Introducing LuxDiT: a diffusion transformer (DiT) that estimates realistic scene lighting from a single image or video.
It produces accurate HDR environment maps, addressing a long-standing challenge in computer vision.
新技術「LuxDiT」を紹介します。これは、たった1枚の画像や動画から、その場のリアルなライティングを推定できる拡散モデル(DiT)です。
このモデルは、コンピュータビジョン分野における長年の課題であった、高精度なHDR環境マップの生成を実現します。
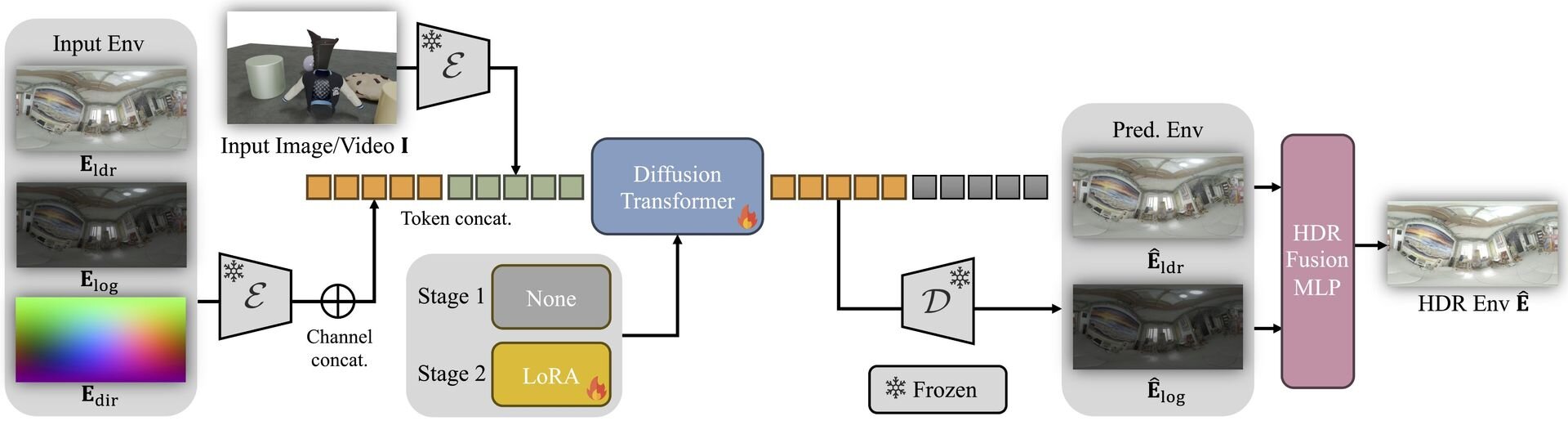
LuxDiT: a video DiT predicting environment maps as two tone-mapped representations, guided by a light directional map. It uses a VAE to encode maps into latents, processes them with visual input, then decodes and fuses outputs with an MLP for HDR panorama reconstruction.
仕組みを少し詳しく説明すると、LuxDiTは映像処理に特化した拡散モデルで、光の方向を示すマップを手がかりに環境マップを予測します。VAE(Variational Autoencoder、変分オートエンコーダ。本質的な特徴を学習して新しいデータを自ら生成するニューラルネットワーク技術)で環境マップの情報を一度圧縮し、入力された映像と一緒に処理します。その後、軽量なMLP(Multi-Layer Perceptron、多層パーセプトロン。人間の脳神経回路を模した基本的なニューラルネットワーク構造)ネットワークを使って最終的なHDRパノラマとして復元します。

LuxDiT achieves state-of-the-art results, reducing error in predicting sunlight direction by nearly 50% compared to existing techniques. Qualitatively, LuxDiT recovers more high-frequency details while preserving accurate lighting.
性能はまさに最先端(State-of-the-art)で、特に太陽光の方向を予測する際の誤差を、既存の技術に比べて約50%も削減することに成功しました。画質の面でも、正確なライティングを保ちつつ、より細かなディテールまで鮮明に復元できます。
It's not just for static images! As a video-native model, LuxDiT produces temporally consistent lighting for video inputs. This avoids the flickering common in frame-by-frame methods and enables realistic virtual object insertion in dynamic scenes. pic.twitter.com/ouVzodTK0y
— Ruofan Liang (@RfLiang) September 5, 2025
It's not just for static images! As a video-native model, LuxDiT produces temporally consistent lighting for video inputs. This avoids the flickering common in frame-by-frame methods and enables realistic virtual object insertion in dynamic scenes.
LuxDiTの強みは静止画だけではありません! 映像処理ネイティブのモデルなので、動画に対しても時間的に矛盾のない(スムーズな)ライティングを生成できます。これにより、映像を1フレームずつ処理する方法で起こりがちなチラつきを防ぎ、動きのあるシーンでもリアルなCGオブジェクトを合成することが可能になります。
LuxDiT, like our earlier works #DiffusionRenderer and #UniRelight, is another exploration into using generative models for inverse rendering, enabling high-quality lighting estimation from casually captured footage.
LuxDiTは、私たちが以前発表した「DiffusionRenderer」や「UniRelight」と同様に、生成AIモデルをインバースレンダリング(完成画像・映像からシーンの構成要素を逆に推定する技術)に応用する研究の一環です。この技術により、普段何気なく撮影した映像からでも、高品質なライティングを推定できるようになります。
■LuxDiT: Lighting Estimation with Video Diffusion Transformer(プロジェクトページ、英語)
https://research.nvidia.com/labs/toronto-ai/LuxDiT/
CGWORLD関連情報
●NVIDIAが3DGS技術「LongSplat」発表! スマホで撮影したカジュアルな動画から空間の3DGSモデルを生成し、自由な視点の映像をつくり出す

国立陽明交通大学とNVIDIAの研究チームが、スマートフォンなどで気軽に撮影した長尺かつ複雑な動きを含む動画から3D Gaussian Splattingモデルを生成し、新しい視点の画像を生成するフレームワーク「LongSplat」を発表。GitHubではNVIDIAライセンスでコードが公開されている。
https://cgworld.jp/flashnews/01-202509-LongSplat.html
●図面・スケッチからリアルな建築ビジュアルを生成! アリババのオープンソース画像編集AIモデル「Qwen-Image-Edit」活用例
アリババグループが画像生成機能「Qwen-Image-Edit」を使って図面・スケッチからリアルな建築ビジュアルを生成する活用例をXに投稿。Qwen-Image-Editは8月19日(火)に公開された、テキストの指示のみで写真の修正やクリエイティブな変更が可能な新しいAI画像編集モデル。AIアシスタント「Qwen Chat」で誰でも利用可能なほか、GitHubではオープンソース(Apache-2.0ライセンス)でコードが公開されている。
https://cgworld.jp/flashnews/01-202509-Qwen-Image-Edit.html
●NVIDIA、新リライティングフレームワーク「UniRelight」発表! 入力画像または動画からシーン特性と照明分布を分析し高品質なリライトを実現

NVIDIA、トロント大学、Vector Instituteからなる研究チームが新しいリライティング(再照明)フレームワーク「UniRelight」を発表。1枚の入力画像または動画からシーンの固有特性と照明分布を共同でモデル化することで、高品質なリライティングと固有分解を可能にする。
https://cgworld.jp/flashnews/01-202507-NVIDIA-UniRelight.html












